Prompt Caching: Just do it.
Rotterdam, March 29th 2026
Motivation
I am young enough that I still had masters courses past the GPT 3 / ChatGPT launch, so naturally I took all the AI and Natural Language Processing courses I could. Apparently those were wasted on me, because I can remember the distinct moment in 2025 in which I looked at Claude Code's token usage statistic for the first time: "input tokens, output tokens, cached input tokens".
Wait, cached input tokens?
That can't be right. How can you cache something that needs to understand the full context every time? If I cache something, how will that something know about the new tokens?
I put it off as magic and went on with my life.
Recently though, the topic of prompt caching came up in my work context, which made me to get back to understanding into the inner workings of LLMs and leading me to spending a lot of my time also reading and thinking about the security implications of prompt caching. This Article tries to structure my thoughts into a decision framework that contextualises the efficacy of prompt caching for a certain use case.
What this is
- A decision framework for prompt caching. When to cache what in your LLM application, with the security tradeoffs at each step. I'll explain just enough about how caching works to make the reasoning make sense, and then walk through the actual decisions.
What this is not
- An in-depth explanation of prompt caching. We will just talk about the basics needed to understand my points. Understanding prompt caching deeply, especially on a technical level, requires a much longer read. I will link some of my favourites.
- A guide to optimise cache hits. Maybe I will write a post about this in the future, but there are great guides on this already and the provider docs are very good nowadays.
- A provider comparison. I'm not going to walk through every provider's caching implementation, pricing, and TTLs. Those might change at any point, and the security reasoning applies regardless of which provider you use.
What even is prompt caching?
To understand prompt caching, we need to first understand what it's caching, and to understand that, we need to zoom out to how LLM inference works at a high level.
When you send a request to a model, the part of the inference that we care about can be split into two stages:
- Prefill phase: The model processes all your input tokens at once, building up an internal representation of the input.
- Decode phase: The model generates output tokens one at a time, each one attending to everything that came before it.
Even though the prefill phase is "just" one big linear algebra calculation, the scale of these matrix multiplications can get enormous and scales quadratically with the input length. So for longer prompts the prefill phase takes far more total compute compared to generating a few hundred output tokens, even though each individual decode step is more expensive. A 100k token prompt means 100k tokens worth of computation before the model even starts responding.
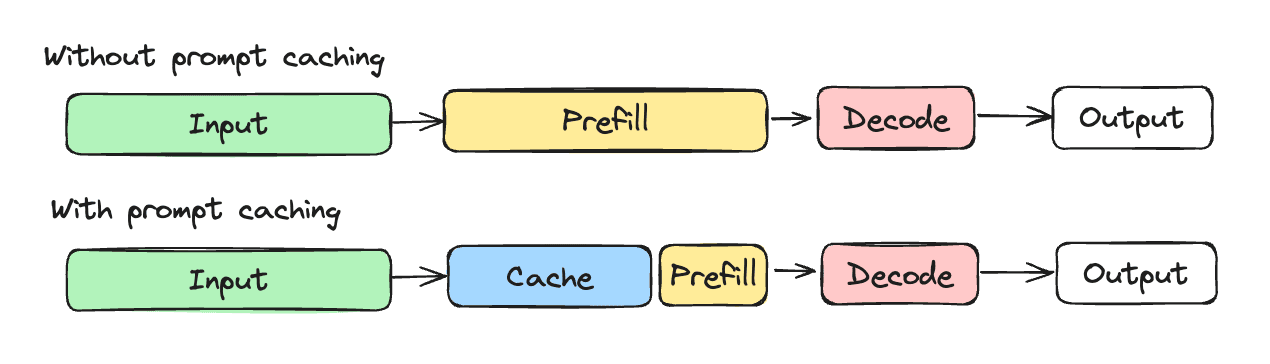
This is where prompt caching enters. During the prefill phase, the model computes what are called key-value pairs (KV pairs) for each token. Without getting into the linear algebra, think of it this way: each token's KV pair encodes what that token "knows" about every token that came before it. These pairs are what the model uses during attention, they're the mechanism by which the model understands context.
Now, the only thing we really need to understand here for prompt caching: In a decoder-only transformer (which is what Claude, GPT, and most modern LLMs are), attention only flows forward. Token 50 attends to tokens 1-49, but tokens 1-49 don't need to know anything about token 50. That means if you've already computed the KV pairs for tokens 1-49, and a new request comes in with those same 49 tokens at the start, you can just... reuse them. The new tokens at the end will attend to the cached KV pairs just fine, because those cached pairs were never going to look forward anyway. That's what prompt caching is: skipping the prefill computation for the prefix of your prompt that hasn't changed.
This only works because caching is prefix-based. The cache checks your prompt from the very first token, moving forward sequentially. As long as the tokens match a previously cached prefix, you get a cache hit for that portion and only compute the rest. The moment the tokens diverge, the cache stops matching. This means order matters, because the exact same content rearranged in a different order is a complete cache miss.
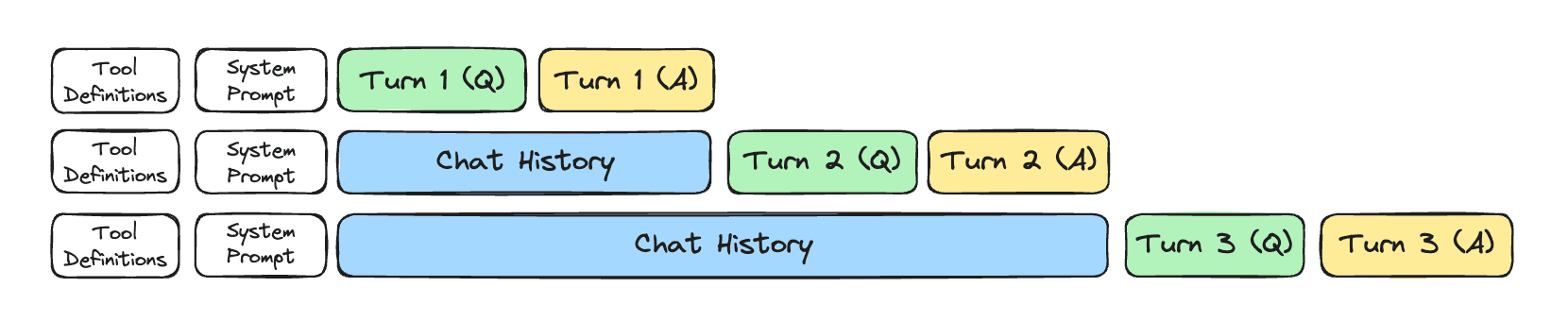
This is why prompt caching is particularly powerful for multi-turn conversations and agentic workflows. Think about a typical API request: it starts with tool definitions, then your system prompt, then the full message history, and finally the new user message at the end. On every turn, the only thing that changes is the latest message, everything before it is identical to the previous request. With caching, the model skips the prefill for the entire conversation history and only computes the new turn. In agentic loops where the model might make 10-15 internal tool calls before responding to the user, that's 10-15 requests where almost the entire prompt is a cache hit.
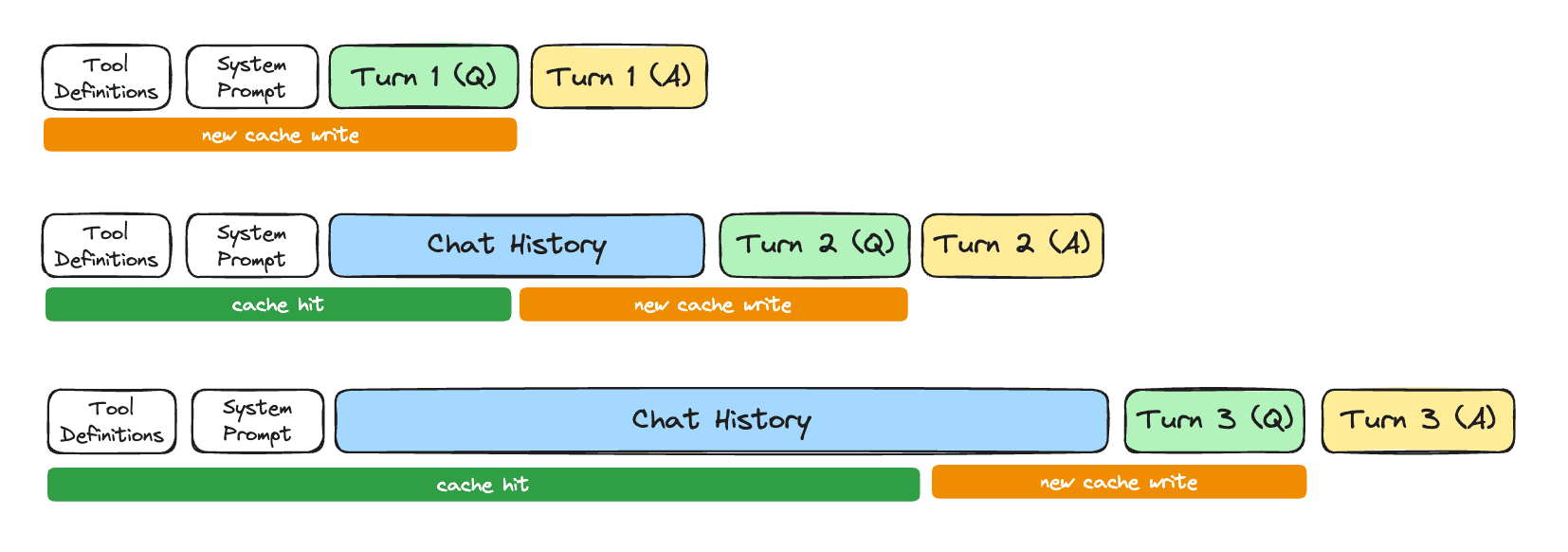
One note on how the two biggest providers handle this handle this at time of writing: Anthropic gives you explicit control over what gets cached through cache_control breakpoints. OpenAI caches automatically on every request over 1,024 tokens and it's not really configurable. From our perspective it works the same: stable content at the front of the prompt, changing content at the end.
What to be careful about
There is one thing that could theoretically make prompt caching unsafe, assuming we trust the provider itself: timing side channel attacks.
Quick note on that "trust the provider" assumption: a compromised provider could dump the cache and leak everything in it, but that's a precondition of using them at all. If that tradeoff isn't acceptable for your use case, you should be running an open-weight model yourself on something like vLLM or SGLang.
A cached response comes back faster than an uncached one. That latency difference is measurable. If someone can send requests and measure the time-to-first-token, they can probe whether a particular prefix exists in the cache.
To be a bit more concrete: Imagine a multi-tenant application where User A submits a form with their name, email, phone number. That conversation, including the form values, gets cached as part of the messages array. Now an attacker in the same account crafts prompts that try to reconstruct those form field values as prefixes. "name: John, email: john@..." comes back fast, cache hit. "name: Jane, email: jane@..." comes back slow, cache miss. Do this enough times, and you can reconstruct what User A submitted.
Cross-account, this is largely a solved problem. There's a growing body of research on timing side channels in prompt caching, and it's had real impact: researchers demonstrated full prompt reconstruction with 95% accuracy (Wu et al., NDSS 2025), stole system prompts from production services including Claude, DeepSeek, and Azure OpenAI with 89% accuracy (Song et al., IEEE 2025), and the original Stanford audit led to at least five providers changing their caching implementations (Gu et al., ICML 2025). Providers now scope caches to the account level, so two different accounts won't share cache entries.
But inside your account, meaning inside the application you're building, this is still possible.
Now, this sounds scarier than it probably is for most applications. The framework below helps you figure out if it matters for your specific setup, and what to do about it if it does.
The Decision Framework
System prompt and tool definitions: not a problem
This is the simplest case in my Opinion. Your system prompt and tool definitions are either the same for all users or they contain user-specific data.
If they're the same for everyone, sharing cache is fine. There's nothing to leak. Every user hitting the same cached system prompt is exactly the behavior you want.
If they contain user-specific data, they won't match across users anyway. Different content means different tokens means different prefix means no shared cache hit. The "attack" requires a matching prefix, and it just won't match.
So regardless of your situation, caching system prompt and tool definitions is safe. Do it.
The messages array: this is where it gets interesting
The messages array is where the real cost savings live, especially in multi-turn and agentic workflows. It's also where user data lives. So this is the one part of your prompt where caching creates a potential security tradeoff.
Does your messages array contain sensitive user data? If not, cache it, you're done. Move on. This covers a surprising number of applications, things like internal tools, dev environments, anything where the "users" are your own team.
But if it does contain sensitive data (and for most user-facing applications, it will), the question becomes: is the timing side channel actually exploitable in your setup?
How exposed are you?
For the timing attack to work, three things need to be true at the same time:
-
The user can influence what goes into the messages array. If your system constructs the prompts entirely server-side and users can't control the content, there's no way to send probes.
-
Rate limits are weak or nonexistent. The timing attack needs many requests to average out network noise and get a clean signal. Tight rate limits make this impractical.
-
The user can observe the timing. If your user is talking to an agent that takes 30 seconds to respond, they're not going to notice a 100ms timing difference buried in fifteen API calls. This really only matters if the user's input maps pretty directly to a single model call and they can see the raw response time.
If any of those is a no, you're fine to cache the messages array normally. The attack surface doesn't exist in practice.
If all three are true, you're in the small minority of applications where this actually matters. And even then, there's a straightforward fix.
DIY cache salting
In my opinion everything this problem is easily solved by injecting a unique user identifier at the very beginning of the messages array. Server-side, outside the user's control. Something like a UUID tied to the user's account.
Because caching is prefix-based, this breaks the prefix for every other user. User A's messages array starts with [tenant:abc-123][...] and User B's starts with [tenant:def-456][...]. The cache diverges at the very first token of the messages. No timing signal, no shared cache hits on the sensitive part.
The nice thing about doing this at the start of the messages array (rather than in the system prompt) is that you keep shared caching on everything before it. Tool definitions and system prompt are still shared across all users, saving you tokens. You only isolate the part that actually contains sensitive data.
You lose shared caching across users for the messages portion, but that's a tradeoff worth making if you're handling sensitive data in a multi-user application. And in most multi-turn conversations, the messages are user-specific anyway, so you weren't going to get cross-user cache hits there regardless.
One thing to keep in mind: the model will see that identifier as the first message. Frame it in a way the model can ignore, or instruct it to disregard metadata tokens in your system prompt. Or even better, maybe make it be something informational for the model by passing information about the user that can help for personalisation or similar.
Closing
Prompt caching is one of those optimizations that's almost always worth doing. The cost savings and latency improvements are significant, especially for agentic and multi-turn workflows. For the vast majority of applications, you should cache everything and not think twice about it.
For the minority of applications where you're handling sensitive user data, your users have direct prompt access, and rate limits are loose, the timing side channel is real but manageable. Salt the beginning of your messages array with a tenant identifier and you've eliminated the attack surface while keeping most of the caching benefits.
One thing this post doesn't cover is the economics of caching. There are cases where it's actually cheaper to not cache certain parts of your prompt, depending on your provider's pricing for cache writes vs reads. But if you're building a multi-turn agent, the cost savings from caching the messages array are almost always worth it, and that's the use case this framework is written for.
The research in this space is still evolving. I'd like to see providers document their cache isolation models in more detail and offer native per-tenant salting as a first-class feature. But until then, you have the tools to handle it yourself.
References
- Gu, C. et al., "Auditing Prompt Caching in Language Model APIs," Stanford, ICML 2025. arXiv:2502.07776
- Wu, G. et al., "I Know What You Asked: Prompt Leakage via KV-Cache Sharing in Multi-Tenant LLM Serving" (PROMPTPEEK), NDSS 2025. Paper
- Song, J. et al., "The Early Bird Catches the Leak: Unveiling Timing Side Channels in LLM Serving Systems," IEEE 2025. arXiv:2409.20002
- Luo, S. et al., "Shadow in the Cache: Unveiling and Mitigating Privacy Risks of KV-cache in LLM Inference," NDSS 2026. arXiv:2508.09442
- Wu, X. et al., "Cache Me, Catch You: Cache Related Security Threats in LLM Serving Frameworks," NDSS 2026. Paper